
1. AI Accelerator Architecture
The most import processor family, CPU, was designed to process common processing work and it is not enough to handle mass computational work. It is designed to process 2 data per cycle at the beginning, and some other extensions with higher computation power has been added later, but CPU is still very far from the requirement of AI work.
To accelerate computational intensive work, different kinds of accelerators have been designed to achieve higher performance.
1.1. Vector * Vector
Vector Cores are the most basic computation unit in GPU and GPGPUs, they are called CUDA cores in Nvidia platform. Instead of processing element by element, Vector Cores process one group/array of data per instruction. For example, in Nvidia SIMT-32 architecture, each instruction will execute 32 threads simutaneously, and for the Vector multiplication operation shown below with $N=32$, each $A[i]$ and $B[i]$ with $0<=i<32$ is sent to one lane of the Vector Core.
\[D[N-1 : 0] = A[N-1 : 0] \times B[N-1 : 0]+ C[N-1 : 0]\]As Vector core can computer a group of data per instruction, Vector Core has much higher computation density than CPU.
1.2. Vector * Matrix
With the emerging of AI, many NPU are designed to accelerate the Convolution and MMA computation. The most commonly used architecture in early days are the $Vector \times Matrix$ NPU. It computes the following equation with $A[M-1 : 0][K-1 : 0]$ is a $M \times K$ matrix, while $B[K-1 : 0]$ is a K element vector. This operation yields a Vector $D[M-1 : 0]$ per cycle.
\[D[M-1 : 0] = A[M-1 : 0][K-1 : 0] \times B[K-1 : 0] + C[M-1 : 0]\]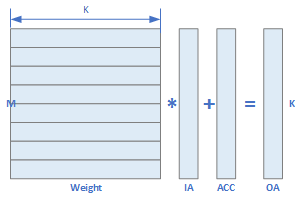
This $Vector \times Matrix$ processor has $M \times K$ multipliers, and comparing with $Vector \times Vector$ processor, it has much higher computation density. In many AI acclerators like NPUs (Neural Processing Unit), $Vector \times Matrix$ is the kernel computation unit and the most famous one is from Cambricon in this paper, which opens of the door of AI accelerators.
In the above architecture, the $NBin$ contains the vector with size $T_n$ and the $SB$ contains the matrix with size $T_n \times T_n$. During the computation, the IA would be broadcasted to Weight data.
1.3. Matrix * Matrix
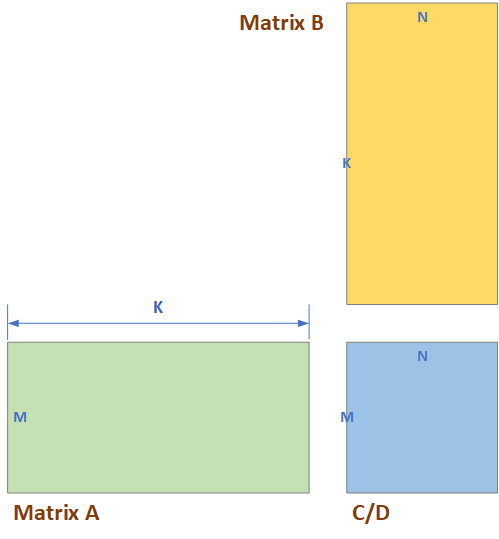
While most of the computation in AI can be transferred to MMA operation, processor with $Matrix \times Matrix$ operation are the mainstream of AI accelerator today. It computes the following operations:
\[D[M-1 : 0][N-1 : 0] = A[M-1 : 0][K-1 : 0] \times B[K-1 : 0][N-1 : 0] + C[M-1 : 0][N-1 : 0]\]In tihs equation, the size of matrix $A$ is $M \times K$, the size of $B$ is $K \times N$ which the size of C and D is $M \times N$. It has $M * N * K$ multipliers in each MMA unit, thus is has much higher computation density than Vecotr Core and $Vector \times Matrix$ unit.
The most important accelerator using $Matrix \times Matrix$ architecture is Tensor Core in Nvidia’s GPUs, and it is always shown as this picture.

The Green cubes and the Pulple cubes can be seen as the IA and Weight data, and the blus cubes in the middle stand for the multipliers. This Tensor Core shows a $8 \times 8 \times 8$ MMA unit.
1.4. Systolic Array
Systolic Array is a special MMA processor, but it has the same number of multipliers as $Vector \times Matrix$. It is not a new technology. The most important AI processor using Systolic Array is the TPU from Google.
It attracts the attention because of power problem in ASIC. By sending the data into multipliers at the same cycle, the multipliers will start to work at the same time, and the emerging current will give pressure to the power supply circuits in ASIC. We call this $\frac{D_i}{D_t}$ or Di/Dt for simplicity in chip design. Instead of send all data into multipliers in one cycle, like in Tensor Core, data are feed into the multipliers one by one in Systolic Array, and they “flow” in the multiplier array.
An example of $4 \times 4 \times 4$ systolic array is shown in the following picture.

Advantage:
- The circuit starts slowly, and will not cause Di/Dt issue.
Disadvantage:
- The number of multipliers is much smaller than Tensor Core.
- The latency is much longer than Tensor Core. The above figure shows that it takes 4 cycles in total to feed the data into multipliers.
1.4.1 Systolic Array Plus MMA
To solve the problem of Systolic Array and make use of its advantages, an architecture which combines the Systolic Array and Tensor Core was designed. It’s architecture is shown as below.

The original Systolic Array has the most basic element as data, which this new design has a small MMA cubis as its most basic element. Instead of sending one element per cycle, one matrix of A and B are sent to Systolic Array each cycle. The advantages of this design is:
- It has higher computation density;
- It has better power than the Tensor Core which has the same number of multipliers.
1.5. Comparison of Different Processor
Let us compare different kinds of acceleraters in names of Data Reuse Ratio and other benchmarks. Data Reuse Ratio is defined as the ratio of number of multiplications and the size of data.
| Accelerator Type | Multiplier Num | Data size | Data Reuse Ratio (Mul/Data) | Data Dimension | Multipliers Dimension |
|---|---|---|---|---|---|
| CPU | 1 | 2 | 0.5 | 0 | 0 |
| Vector Core | N | 2*N | 0.5 | 1 | 1 |
| Vector $\times$ Matrix | M * K | M*K + K | $\frac{N}{N+1}$ | 1, 2 | 2 |
| MMA | M * N * K | MN + NK | $\frac{N}{2}$ | 2 | 3 |
| Systolic | M * N | MN + NK | 0.5 | 2 | 2 |
From the above table, it is clear that Tensor Core has the highest Data Reuse Ratio, that is why it is the most popular architecture today.